4.1. K-Nearest Neighbours and K-Means Clustering#
In this lesson we’ll be looking at more machine learning techniques:
K-nearest neighbours regressor - supervised learning
K-nearest neighbours classifier - supervised learning
K-means clustering - unsupervised learning
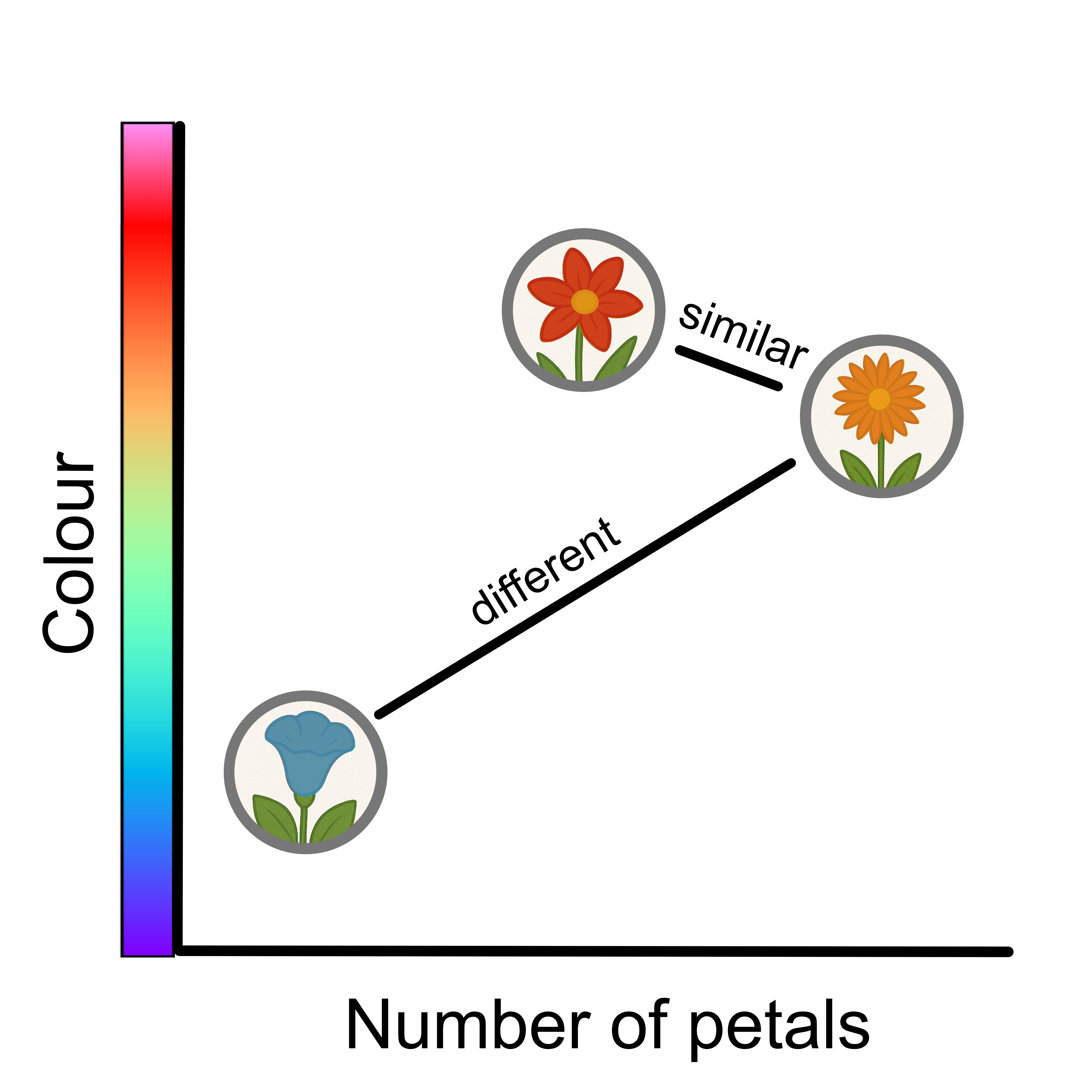
The core concept underpinning these models is the idea that the distance between datapoints is a measure of similarity.
4.1.1. Glossary#
- K-nearest neighbours#
A machine learning algorithm that makes predictions using similar samples nearby in the training data.
- Distance#
A measure used to compare how close or similar samples are.
- Similarity#
How alike samples are, often measured using distance.
- K-means clustering#
An unsupervised learning algorithm that automatically groups data using the distance between samples to measure similarity.